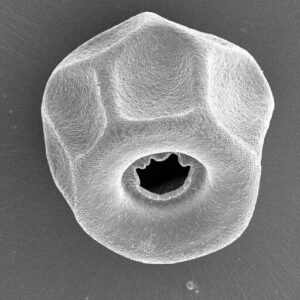
A 200-year nomenclatural trainwreck
On a recent trip to the eastern coast of James Bay, I collected large numbers of testate amoebae that, by morphological criteria, belong to various species in the genus Difflugia. I’ve spent some time making portraits of them, measuring them, and dropping live ones in little vials of guanidinium thiocyanate in the hope of eventually…